Trackmate
NB : This document will always be a work in progress as we are using an agile methodology.
The main purpose for the implementation of Trackmate is to have a system that can handle thousands of requests from
possibly millions of concurrent users , firing various events from web pages on a desktop to mobile devices.
The system will stream these events without any intervention to the payload and then consume these events
and push them to various backend systems.
The event payload will be in json format and will be implemented with a generic vanilla Javascript (refered to as our SDK),
that can be used on any web browser, device and operating system.
The SDK will be lightweight, robust and simple to implement and use.
Context Diagram of Trackmate
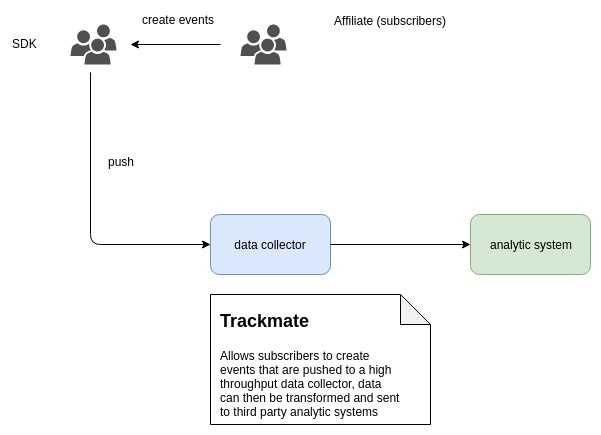
Use Case The main feature of the Trackmate design :- To capture all events on front end systems from subscribers/end-users so that we can create useful behavioral patterns and usage analytics for eventual consumption by an affiliate. The following are the foreseen beneficial outcomes Move to near or real time data analytics (feedback) Benefit in user engagement Benefit the affiliate to make informed decisions on efforts/campaigns User Stories As a marketing Intelligence agent / marketer I want an easy to use and implement SDK so that I can make informed decisions about a campaign. As a service team we want to capture useful data/data points at high throughput so that we can offer a useful scalable data capture system to affiliates. As a service team we want to capture useful data/data points to our backend systems so that we can offer useful valuable data to our affiliates.
The software architecture overview will best be described in the following diagram
Architecture Overview Diagram
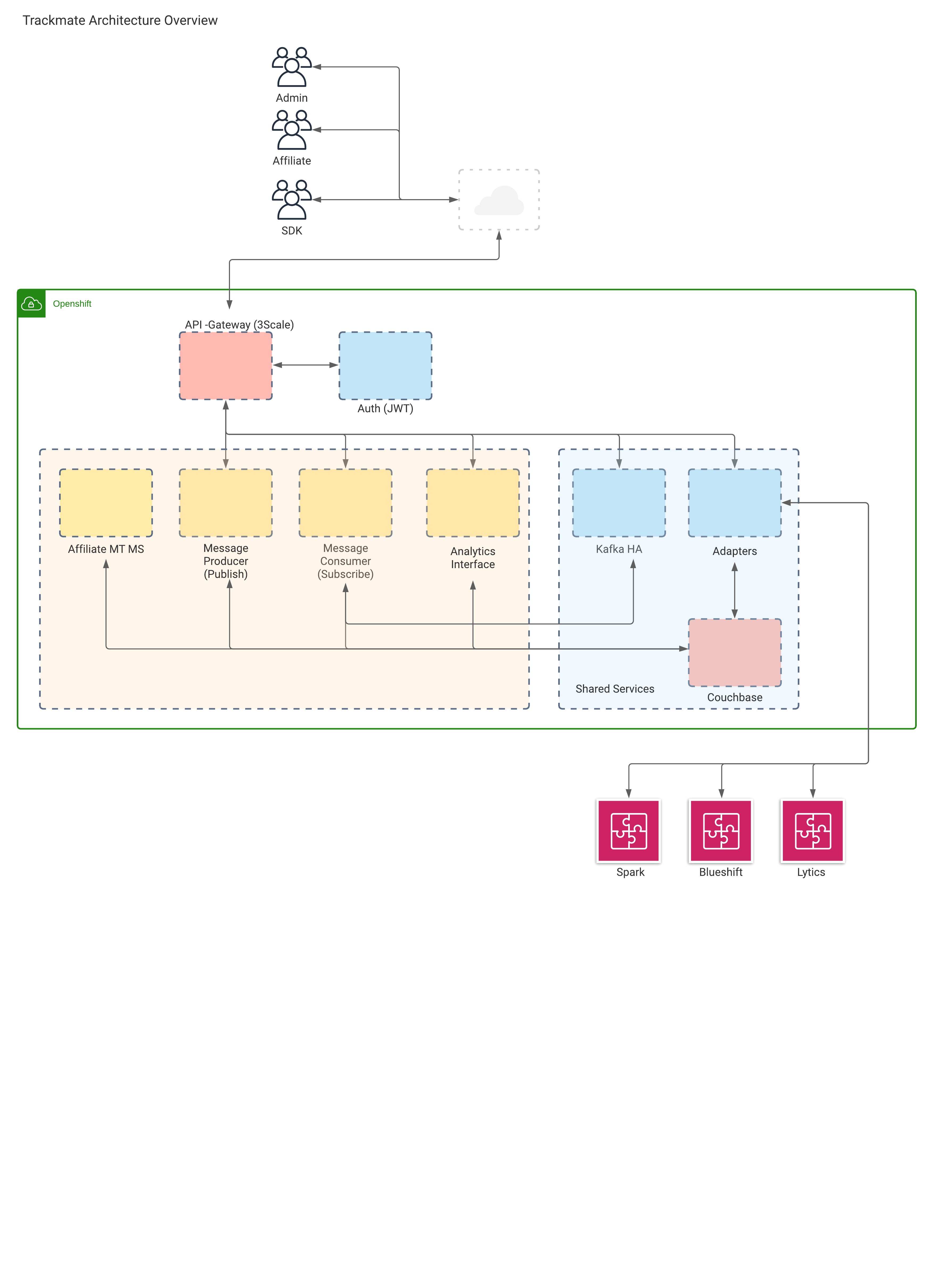 Overview Description
The software architecture is broken up into several items.
We will discuss the 3 main parts of the overall Trackmate system.
A. SDK (Generic Javascript library)
Dependencies for Vuejs
Dependencies for Reactjs
Dependencies for Angularjs
Vanillajs
SDK (Native implementation)
IOS
Android
B. Data Collection (BE)
The backend consist's off a HA (high availability) and scalable (horizontal and vertical) Kafka broker publish and subscribe
with anti - affinity or session spread, each with and independent zookeeper instance (Based on the strimzi project here).
A microservice that will handle high volumes of json data (RESTAPI) known as a message producer , this microservice can
be scaled to the hardware limits of the underlying node. The second microservice is a consumer, it acts on
published events from the messaging queue for a specific TOPIC and can translate data to any format and push to
analytic systems or data backends.
C. Analytics (BE)
We will make use of RestAPI calls to backend systems from the consumer microservice
Architecture Deploy Detail Diagram
Overview Description
The software architecture is broken up into several items.
We will discuss the 3 main parts of the overall Trackmate system.
A. SDK (Generic Javascript library)
Dependencies for Vuejs
Dependencies for Reactjs
Dependencies for Angularjs
Vanillajs
SDK (Native implementation)
IOS
Android
B. Data Collection (BE)
The backend consist's off a HA (high availability) and scalable (horizontal and vertical) Kafka broker publish and subscribe
with anti - affinity or session spread, each with and independent zookeeper instance (Based on the strimzi project here).
A microservice that will handle high volumes of json data (RESTAPI) known as a message producer , this microservice can
be scaled to the hardware limits of the underlying node. The second microservice is a consumer, it acts on
published events from the messaging queue for a specific TOPIC and can translate data to any format and push to
analytic systems or data backends.
C. Analytics (BE)
We will make use of RestAPI calls to backend systems from the consumer microservice
Architecture Deploy Detail Diagram
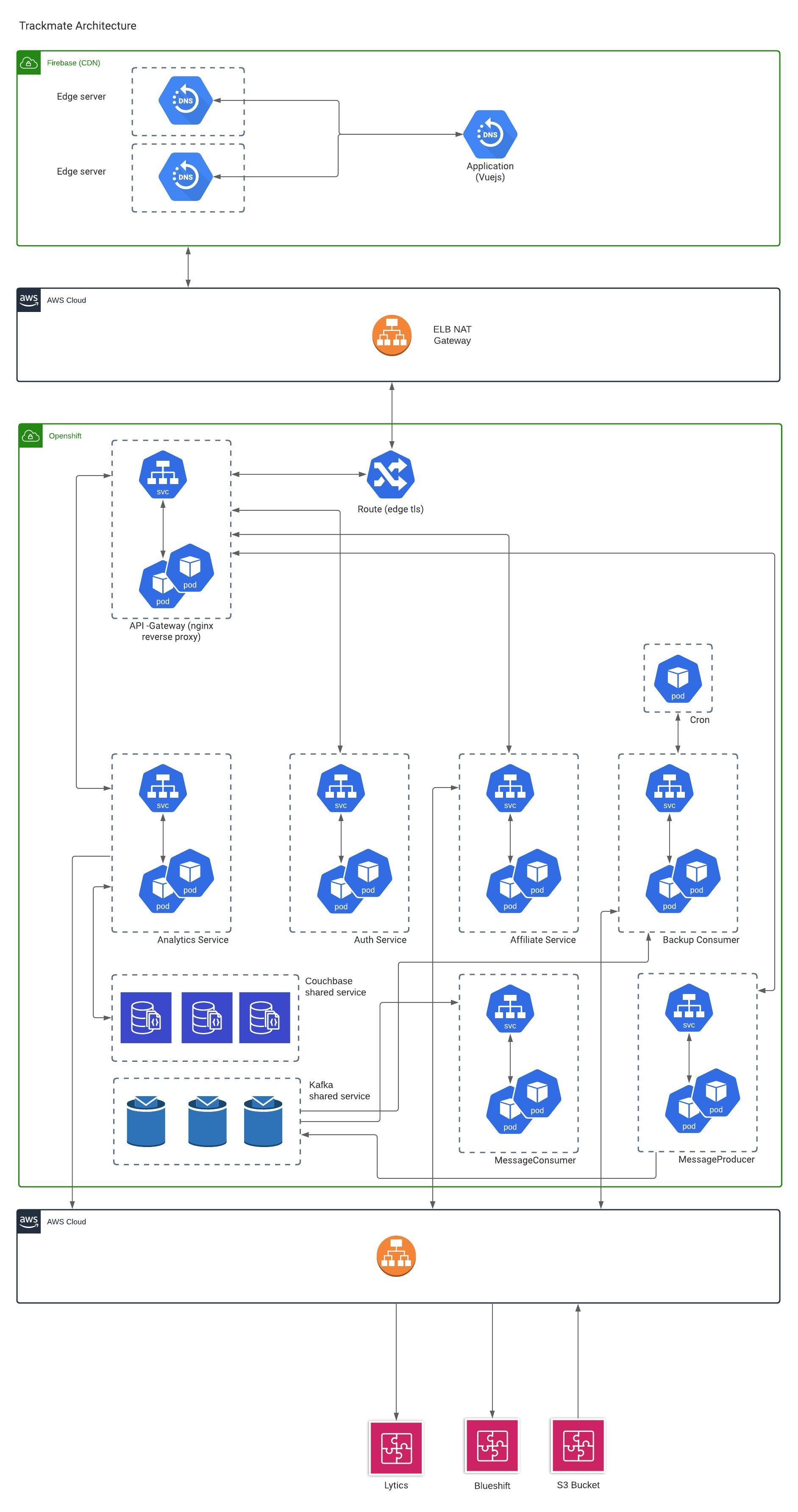
Overview We will be using couchbase as a document store. As we are pushing event data with various payloads. This means we can have an open schema system that will allow for flexibility. The partitions for each "Bucket" or json Document Database will be set for each afiliate (Affiliate name and ID). The storage will support multi-tenancy i.e it will have all affiliate related events but be partitioned in such a way that only a specific affiliate can see or access their data and their data only. Couchbase was chosen as it has separate process's for DBManagement, Query and Analytics. This means we can make intensive queries and analytic calls without affecting the DB manager.
db.createUser({ "user" : "pt", "pwd": "pt", "roles" : [{"role" : "readWrite", "db" : "myportfolio"}]});